داده کاوی در SQL

مقدمه
بطور کلی داده کاوی به دو قسمت زیر تقسیم میشود:
- اهداف توصیفی (Descriptive Goal)
بدنبال یافتن الگوها و روابط بین دادهها هستیم، بدین ترتیب مدلی برای توصیف بهتر دادهها بدست خواهد آمد.
- اهداف پیش بینانه (Predictive Goal)
بدنبال انجام پیش بینی با استفاده از الگوها و مدلهای فوق هستیم.
همچنین مراحل اجرای یک پروژه داده کاوی شامل مراحل زیر است:
- تحلیل
مهم ترین فعالیت در این فاز، فهم عمیق مسئله و شناخت درست مسئله و شناسائی مفاهیم کلیدی (Key Concept) در مسئله است.
- طراحی
مهم ترین فعالیت این فاز، فرموله کردن مسئله با استفاده از مفاهیم کلیدی است.
- پیاده سازی/ نگهداری و بهبود
SQL Server
در یک چرخه عمر جریان داده معمولی ، داده ها از سیستم های منبع رابطه ای / غیر رابطه ای به سیستم های OLAP منتقل می شوند که از لایه های انبار داده ها و داده های اطلاعات عبور می کنند. سیستم های هوش تجاری از سیستم های پردازش داده های تحلیلی برای تجزیه و تحلیل حجم زیادی از داده ها استفاده می کنند که به طور کلی برای تجزیه و تحلیل داده های بسیار سریع از قبل جمع می شوند. این امر برداشت بسیاری از متخصصان را از لحاظ نیاز به تجزیه و تحلیل داده ها از نظر اشباع به همراه می آورد. نکته کلیدی که در تصویر کلان از دست رفته است این است که تجزیه و تحلیل داده ها به توانایی کاربر نهایی در تجزیه و تحلیل داده ها و تعیین تجزیه و تحلیل بستگی دارد.
به طور کلی روش های استفاده شده توسط کاربران تجاری برای برش و تکه کردن واقعیت های مختلف قابل اندازه گیری / KPI با ابعاد مختلف ، استفاده از تجسم های مختلف برای تجزیه مسئله و شناسایی فضای مسئله ، تجزیه و تحلیل روند مبتنی بر زمان و غیره است. همه این روش ها از محاسبات و تجزیه و تحلیل آماری ساده استفاده می کنند . شاخه ای از علوم آماری وجود دارد که می تواند با استفاده از الگوریتم های پیچیده تخصصی که برای دسته بندی متمرکز مشکلات طراحی شده اند ، الگوها را در حجم زیادی از داده ها کشف کند ، که به عنوان تجزیه و تحلیل پیش بینی نیز شناخته می شود. بر اساس الگوهای مشخص شده ، داده ها برای اهداف پیش بینی و پیش بینی استخراج می شوند. این شاخه از علم داده عموماً با عنوان Data Mining شناخته می شود.
هدف از داده کاوی شناسایی الگوها و مجموعه داده برای یک دامنه خاص از مشکلات با برنامه نویسی مدل داده کاوی با استفاده از الگوریتم داده کاوی برای یک مشکل خاص است. هنگامی که فضای مسئله مشخص شد ، حتی می توان از ماشین یادگیری برای طراحی سیستمی استفاده کرد که بتواند الگوها را در مجموعه داده داده شده با اتوماسیون بسیار بیشتر و بدون نیاز به برنامه نویسی تخصصی برای هر مسئله خاص استخراج کند.
داده کاوی چیست؟
تعاریف متعددی برای داده کاوی با توجه به مشاغل و همچنین دانشگاهیان وجود دارد. داده کاوی روشی است که به طور خودکار حجم زیادی از داده ها را جستجو می کند تا رفتارها ، الگوهای و روندهایی را کشف کند که با تجزیه و تحلیل ساده امکان پذیر نیست. داده کاوی باید به مشاغل اجازه دهد تصمیمات مبتنی بر دانش و دانش محور بگیرند که این مکان را بهتر از رقبای خود رقم بزند.
انبار داده ، از زمان وظیفه خود برای ذخیره حجم زیادی از داده ها از جمله آخرین سال داده ها. انبار داده برای تجزیه و تحلیل توصیفی (آنچه اتفاق افتاده است) و تجزیه و تحلیل تشخیصی (چرا این اتفاق افتاده است) استفاده می شود. با این حال ، کسب و کار نیاز به تجزیه و تحلیل فراتر از آن دارد. داده کاوی را می توان برای تجزیه و تحلیل پیش بینی (چه اتفاقی خواهد افتاد) و آنالیز تجویز (چگونه می توانیم آن را عملی کنیم) استفاده کرد.

مراحل کاری داده کاوی بر اساس استاندارد CRISP-DM
محصول مشترک شرکتهای SPSS, Teradata, NCR و دایملر- کرایسلر است و یک فرآیند استاندارد Cross-Industry برای داده کاوی است که به طور گسترده ای استفاده میشود. مراحل کاری در این مدل به شش فاز اصلی به شرح زیر تقسیم میشوند:
- درک پروژه و فهم حوزه کاربرد (Business Understanding)
به طور صریح و آشکار اهداف و نیازمندیها مشخص میشود. ترجمه اهداف و محدودیت آن در قاعده سازی، تعریف مسئله داده کاوی و مهیا کردن استراتژی اولیه برای نائل شدن به اهداف در این مرحله تعریف می شود.
- انتخاب دادهها (Data Understanding)
این مرحله شامل جمع آوری دادهها برای استفاده از تحلیل اکتشافی و مشخص کردن اطلاعات اولیه برای ارزیابی دادههای با کیفیت و انتخاب دادههای مفید و مورد نیاز میباشد.
- آماده سازی دادهها (Data Preparation)
آماده کردن دادههای اولیه خام به دادههای نهایی، این دادها در کلیه مراحل بعدی استفاده میشود و از این نظر این مرحله تحلیل و تلاش بیشتری را میطلبد. انتخاب عناصر و شناسههای تحلیل شده را برای کاوش دادهها اختصاص میدهیم و با تمیز کردن دادههای خام آن را برای ابزارهای مدل سازی آماده می کنیم.
- مدل سازی (Modeling)
با انتخاب و به کار بستن تکنیکهای مدل سازی مناسب و روش داده کاوی معین نتایج مدل سازی را بهینه می کنیم، که در صورت نیاز میتوانیم با برگشت به عقب تحلیل مدل سازی را بهینهتر نماییم.
- ارزیابی (Evaluation)
مشخص کردن اینکه آیا مدل انتخابی، ما را به اهدافمان که در اولین مرحله تعیین کردیم، می رساند. اتخاذ تصمیم راجع به استفاده از نتایج داده کاوی برای اعتبارسنجی نیز در این مرحله انجام می شود.
- استقرار (Deployment)
استفاده کردن از مدل ایجاد شده، برای مثال میتواند تولید یک گزارش ساده از خروجیها را نام برد، و برای یک مثال پیچیده تکمیل کردن پردازش داده کاوی موازی در سایر حوزهها میباشد، که این الگوها به یک دانش مفید و قابل استفاده تبدیل میشوند و پس از بهبود آنها، الگوهایی که کارا محسوب می شوند در یک سیستم اجرایی به کار گرفته خواهند شد.
مراحل کاری داده کاوی در بستر تکنولوژی Microsoft
داده کاوی غالباً به عنوان فرآیند استخراج اطلاعات، الگوها و روندهای موجود در مجموعه ی عظیمی از دادهها یاد می شود. این الگوها و روندها را می توان به عنوان یک مدل کاوشی تعریف نمود. به بیانی دیگر ایجاد یک مدل کاوشی بخشی از فرآیند بزرگتری است که در برگیرنده ی همه مراحل؛ از تعریف مسئله که مدل حل خواهد نمود تا اجرای مدل در محیطهای کاری است.
باید در نظر داشت که تهیه یک مدل داده کاوی، فرآیندی چرخشی، پویا و تکرار پذیر می باشد و ممکن است هر یک از این مراحل آن قدر تکرار شود، تا مدل مناسبی تهیه گردد.

- تعریف مسئله (Defining the Problem)
تعریف روشنی از مشکل و مسئله کسب و کار است. این مرحله شامل تجزیه و تحلیل نیازمندیهای کسب وکار، تعریف دامنه مشکل، تعریف معیارهایی که با آن مدلها ارزیابی خواهد شد و تعریف هدف نهایی پروژه ی داده کاوی است.
- آماده سازی دادهها (Preparing Data)
یکپارچه سازی و پالایش داده هایی است که در مرحله ی تعریف مسئله فرآیند معین شده است. SSIS حاوی تمامی ابزارهای ملزوم برای تکمیل این مرحله میباشد.
- بررسی دادهها (Exploring Data)
به منظور تصمیم گیریهای مناسب در هنگام تهیه مدل، می بایست دادهها را درک نمود و پس از آن می توان تصمیم گیری در مورد وجود دادههای مخدوش در مجموعه داده و در نهایت استراتژی مناسب برای رفع این مشکلات اتخاذ نمود. Data Source view Designer موجود در BIDS حاوی ابزارهای جامعی برای بررسی و شناخت دادهها شامل محاسبه ارقام حداقل و حداکثر، محاسبه میانگین و انحراف معیار و بررسی توزیع دادهها می باشد.
- تهیه مدل ها (Building Models)
پیش از تهیه مدل باید، دادهها را به دو دسته ی دادههای آموزشی و اعتبارسنجی (آزمایشی) تقسیم نمود. از دادههای آموزشی برای تهیه مدل و از دادههای اعتبارسنجی برای آزمایش صحت مدل با ایجاد سوالاتی در مورد صحت پیش بینیها استفاده نمود. پس از تعریف ساختار کاوشی، می بایست به پردازش مدل پرداخته شود و ساختارهای خالی با الگوهایی که مدل را توصیف می نمایند، پُر شوند. این مرحله با عنوان آموزش مدل شناخته می شود.
- بررسی و ارزیابی مدلها (Exploring and Validating Models)
این مرحله شامل بررسی مدلهای ایجاد شده به منظور آزمودن کارایی آنهاست. می توان مدلها را با ابزارهای موجود در Designer از جمله نمودار صعود و یا ماتریس دسته بندی بررسی نمود.
- اجرا و بروزرسانی مدلها (Deploying and Updating Models)
این مرحله شامل اجرای مدل هایی است که بهترین کارائی را در یک محیط عملیاتی داشته اند. پس از استقرار مدلهای کاوشی در یک محیط عملیاتی می توان از این مدلها برای پیش بینی هایی بهره گرفت.
داده کاوی در سرور SQL
SQL Server عمدتاً به عنوان ابزار ذخیره سازی در بسیاری از سازمان ها مورد استفاده قرار می گیرد. با این حال ، با افزایش نیازهای بسیاری از مشاغل ، مردم به دنبال ویژگی های مختلف سرور SQL هستند. مردم به دنبال ذخیره سازی داده ها با SQL Server هستند. SQL Server در حال تهیه یک بستر داده کاوی است که می تواند برای پیش بینی داده ها مورد استفاده قرار گیرد.
SQL Server با ارائه داده کاوی در خدمات تجزیه و تحلیل ، از زمان انتشار نسخه 2000 پیشرو در تحلیل های پیش بینی کننده بوده است. ترکیبی از سرویس های یکپارچه سازی ، خدمات گزارشگری و SQL Server Data Mining یک بستر یکپارچه برای تجزیه و تحلیل پیش بینی فراهم می کند که شامل پاکسازی و آماده سازی داده ها ، یادگیری ماشین و گزارش است. SQL Server Data Mining شامل چندین الگوریتم استاندارد ، از جمله مدل های خوشه بندی EM و K-means ، شبکه های عصبی ، رگرسیون لجستیک و رگرسیون خطی ، درختان تصمیم گیری و طبقه بندی های خلیج ساده و ساده است. همه مدل ها دارای تجسم یکپارچه برای کمک به شما در توسعه ، اصلاح و ارزیابی مدل های شما هستند. ادغام داده کاوی در راه حل هوش تجاری به شما کمک می کند تا در مورد مشکلات پیچیده تصمیم هوشمندانه بگیرید.
مزایای داده کاوی
داده کاوی (که به آن تجزیه و تحلیل پیش بینی و یادگیری ماشین نیز گفته می شود) از اصول آماری کاملاً تحقیق شده برای کشف الگوهای داده شما استفاده می کند. با استفاده از الگوریتم های داده کاوی در Analysis Services روی داده های خود ، می توانید روندها را پیش بینی کنید ، الگوها را شناسایی کنید ، قوانین و توصیه هایی ایجاد کنید ، توالی وقایع را در مجموعه داده های پیچیده تجزیه و تحلیل کنید و بینش جدیدی کسب کنید.
در SQL Server 2017 ، داده کاوی قدرتمند ، قابل دسترسی و با ابزاری است که بسیاری از افراد ترجیح می دهند از آنها برای تجزیه و تحلیل و گزارش استفاده کنند.
ویژگی های کلیدی داده کاوی
SQL Server Data Mining ویژگی های زیر را برای پشتیبانی از راه حل های داده کاوی یکپارچه فراهم می کند:
- چندین منبع داده
برای داده کاوی می توانید از هر منبع داده جدولی استفاده کنید ، از جمله صفحات گسترده و پرونده های متنی. شما همچنین می توانید مکعب های OLAP ایجاد شده در Analysis Services را به راحتی استخراج کنید. با این حال ، شما نمی توانید از داده های یک پایگاه داده در حافظه استفاده کنید.
- پاکسازی یکپارچه داده ، مدیریت داده و گزارش دهی
خدمات یکپارچه سازی ابزاری را برای پروفایل و پاکسازی داده ها فراهم می کند. شما می توانید فرآیندهای ETL را برای تمیز کردن داده ها در مرحله آماده سازی برای مدل سازی بسازید ، و ssISnoversion همچنین باعث می شود که مدل ها مجدداً به روز شود و به روز شود.
- چند الگوریتم قابل تنظیم
علاوه بر ارائه الگوریتم هایی مانند خوشه بندی ، شبکه های عصبی و درختان تصمیم گیری ، SQL Server Data Mining از توسعه الگوریتم های پلاگین سفارشی خود پشتیبانی می کند.
- زیرساخت آزمایش مدل
مدل ها و مجموعه داده های خود را با استفاده از ابزارهای مهم آماری به عنوان اعتبار سنجی متقابل ، ماتریس های طبقه بندی ، نمودارهای بلند کردن و نمودارهای پراکنده آزمایش کنید. به راحتی مجموعه های آزمایش و آموزش را ایجاد و مدیریت کنید.

- ابزارهای مشتری
علاوه بر استودیوهای توسعه و طراحی که توسط SQL Server ارائه شده است ، می توانید از افزودنیهای داده کاوی برای اکسل برای ایجاد ، پرس و جو و مرور مدل ها استفاده کنید. یا مشتری های سفارشی از جمله سرویس های وب ایجاد کنید.
- پشتیبانی از زبان نوشتاری و API مدیریت شده
همه اشیا data داده کاوی کاملاً قابل برنامه ریزی هستند. برنامه نویسی از طریق MDX ، XMLA یا پسوند PowerShell برای خدمات آنالیز امکان پذیر است. برای پرس و جو سریع و اسکریپت نویسی از زبان Data Mining Extensions (DMX) استفاده کنید.
- امنیت و استقرار
امنیت مبتنی بر نقش را از طریق خدمات تجزیه و تحلیل ، از جمله مجوزهای مجزا برای دستیابی به موفقیت در مدل سازی و ساختاری ، فراهم می کند. استقرار آسان مدل ها به سرورهای دیگر ، به گونه ای که کاربران بتوانند به الگوهای دسترسی پیدا کنند یا پیش بینی ها را انجام دهند.

وظایف حل مشکلات تجاری
چند وظیفه وجود دارد که برای حل مشکلات تجاری استفاده می شود. این وظایف عبارتند از طبقه بندی ، برآورد ، خوشه ، پیش بینی ، ترتیب ، و همکار. SQL Server Data Mining دارای نه الگوریتم داده کاوی است که می تواند برای حل مشکلات تجاری فوق الذکر استفاده شود. در زیر لیستی از الگوریتم هایی وجود دارد که در مشکلات مختلف طبقه بندی شده اند.
- طبقه بندی
بسته به ویژگی های مختلف طبقه بندی می شود. به عنوان مثال ، اینکه مشتری بسته به داده های دیگر مانند سن ، جنس ، وضعیت تأهل ، شغل ، تحصیلات واجد شرایط و غیره ، مشتری آینده نگر باشد.
- برآورد
تخمین با استفاده از پارامترها انجام می شود. به عنوان مثال ، قیمت خانه بسته به موقعیت خانه ، اندازه خانه و غیره پیش بینی می شود.
- خوشه
همچنین به عنوان تقسیم بندی نامگذاری شده است. بسته به ویژگی های مختلف گروه بندی طبیعی انجام می شود. تقسیم بندی مشتری مثال تجاری کلاسیک برای خوشه بندی است.
- پیش بینی
پیش بینی متغیر مداوم برای زمان. پیش بینی میزان فروش برای چند سال آینده یک سناریوی بسیار معمول در صنعت است.
- همکار
یافتن موارد یا گروه های مشترک در یک معامله. معامله می تواند یک سوپرمارکت فروشی یا دارو یا فروش آنلاین باشد.
پروژه داده کاوی
بیایید یک پروژه داده کاوی ایجاد کنیم. Microsoft Visual Studio را باز کنید و یک پروژه چند بعدی تحت Analysis Service ایجاد کنید و پروژه Analysis Services Multidimensional and Data Mining را انتخاب کنید. در زیر Solution Explorer برای پروژه ایجاد شده آورده شده است.
منابع اطلاعات
ما باید منبع داده را به پروژه پیکربندی کنیم همانطور که در زیر نشان داده شده است. منبع داده با پایگاه داده نمونه ، AdventureWorksDW2017 ارتباط برقرار می کند.
بعد از ارائه اعتبار به پایگاه داده منبع ، بعدی این است که اعتبار خود را به سرویس تجزیه و تحلیل برای اتصال به پایگاه داده ارائه دهید.
از خدمات آنالیز برای ذخیره سازی مدل های داده کاوی استفاده می شود و سرویس آنالیز فقط از تأیید اعتبار Windows استفاده می کند. از هر چهار گزینه می توان برای ایجاد اتصال لازم استفاده کرد.
با این کار منبع داده را برای پروژه پیکربندی کرده اید و البته می توانید بعداً آنها را اصلاح کنید. همچنین ، می توانید چندین منبع برای یک پروژه ایجاد کنید.
بیشتر بخوانید : آشنایی با داده کاوی (Data Mining)
نمایش منبع داده
مرحله بعدی انتخاب نمای منبع داده است. نمای منبع داده زیر مجموعه ای از جداول یا نماها است. از آنجا که ممکن است به تمام جداول و نماهای پروژه نیاز نداشته باشید ، از نمای منبع داده ، می توانید اشیا needed مورد نیاز را انتخاب کنید.
برای یک منبع داده داده شده باید یک منبع داده انتخاب شده وجود داشته باشد. اگرچه می توانید چندین منبع داده ایجاد کنید ، می توانید فقط یک منبع داده را برای یک منبع نمایش داده وصل کنید. همچنین ، اگر قبلاً یک منبع داده ایجاد نکرده اید ، از جادوگر نمایش داده منبع ، می توانید منبع داده را ایجاد کنید.
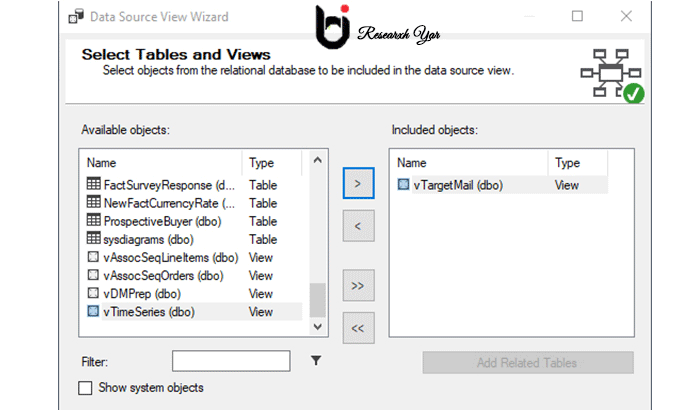
در نمای منبع داده ها ، می توانید اشیاء مورد نیاز خود را از اشیاء موجود انتخاب کنید. می توانید اشیا را فیلتر کنید. اگر جداولی را انتخاب کرده اید که دارای محدودیت کلید خارجی هستند ، می توانید با انتخاب Add Related Table جداول مربوطه را به طور خودکار انتخاب کنید.
مشابه منابع داده ، می توانید چندین منبع منبع داده ایجاد کنید. با این حال ، برای مشاهده منبع داده داده شده می توانید فقط یک منبع داده داشته باشید.
داده کاوی
اکنون تنظیمات اولیه را برای شروع پروژه داده کاوی انجام داده اید. بعدی ایجاد یک پروژه داده کاوی است. مشابه سایر تنظیمات ، ایجاد ساختار داده کاوی با کمک یک جادوگر انجام می شود.
در کادر محاوره ای فوق ، دو نوع منبع وجود دارد ، خواه از یک پایگاه داده رابطه ای یا از مکعب OLAP باشد.
بعد ، تکنیک یا الگوریتم انتخاب می شود.
نه الگوریتم داده کاوی در SQL Server پشتیبانی می شود که محبوب ترین الگوریتم است. با این حال ، متوجه خواهید شد که یک پیشوند مایکروسافت برای همه الگوریتم ها وجود دارد که به این معنی است که می توان انحرافات جزئی یا الگوریتم های معروف را اضافه کرد.
بعدی انتخاب گزینه های Case و Nested است. جدول پرونده جدول است که شامل اشخاصی برای تجزیه و تحلیل است و جدول تو در تو جدول است که شامل اطلاعات اضافی در مورد پرونده است.
بعضی اوقات ، برای اهداف نیازی به همه ویژگی ها ندارید. به عنوان مثال ، ویژگی های آدرس مشتری منطقی نیست که به عنوان یک ویژگی تأثیر پذیر برای تصمیم نهایی ظاهر شود. از صفحه زیر ، می توانید فقط ویژگی هایی را انتخاب کنید که فکر می کنید تأثیرگذار باشد.
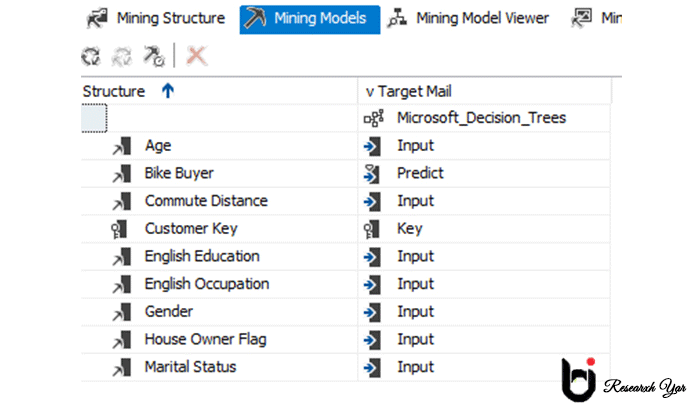
در تصویر بالا ، مشتری اصلی ستون اصلی است در حالی که سن ، خریدار دوچرخه ، فاصله رفت و آمد ، تحصیلات و شغل ورودی هایی هستند که می توانند یک خریدار دوچرخه را ارزیابی کنند یا نه.
اگر در مورد مجموعه داده های خود سرنخی ندارید ، می توانید از دکمه پیشنهاد استفاده کنید و درباره ویژگی های اصلی تحت تأثیر قرار دهید.
برخی از الگوریتم ها با برخی از انواع محتوا کار نمی کنند. به عنوان مثال ، اگر نوع محتوای پیوسته را انتخاب کرده باشید ، Microsoft Naïve Bayes امکان پذیر نخواهد بود.
پنج نوع از نوع وجود دارد مانند مداوم ، دوره ای ، گسسته ، گسسته و مرتب. داده های گسسته فقط می توانند مقادیر صحیح را در نظر بگیرند در حالی که داده های پیوسته می توانند هر مقداری را بگیرند. به عنوان مثال ، تعداد بیمارانی که هر سال توسط یک بیمارستان تحت درمان قرار می گیرند ، گسسته است در حالی که درآمد بیمارستان مداوم است. گسسته سازی به معنای انتقال متغیرهای پیوسته به متغیرهای گسسته است.
هر زمان که مدل داده کاوی ایجاد می شود ، همیشه مهم است که مدل خود را با یک مجموعه داده معتبر آزمایش کنید. مجموعه داده های قطار برای آموزش مدل استفاده می شود در حالی که مجموعه داده های آزمون برای آزمایش مدل ساخته شده استفاده می شود. صفحه زیر نحوه پیکربندی مجموعه داده های آزمون و آموزش را نشان می دهد.
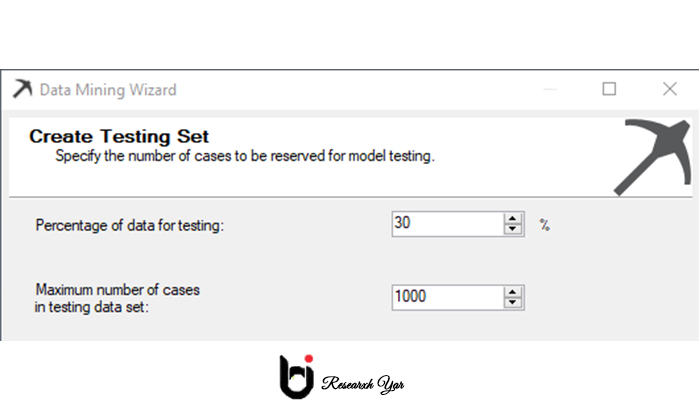
به طور معمول 70/30 تقسیم برای داده های قطار / آزمون است. داده های ورودی بر اساس درصد داده ها برای آزمایش و حداکثر موارد در مجموعه داده های آزمایشی که ارائه می دهید ، به طور تصادفی به دو مجموعه تقسیم می شوند ، یک مجموعه آموزش و یک مجموعه آزمایش. مجموعه آموزش برای ایجاد مدل استخراج استفاده می شود. مجموعه تست برای بررسی صحت مدل استفاده می شود.
درصد داده ها برای آزمایش ، درصد موارد اختصاص یافته به مجموعه آزمایش را مشخص می کند. حداکثر موارد در مجموعه داده های آزمایش تعداد کل موارد در مجموعه آزمایش را محدود می کند. اگر هر دو مقدار مشخص شده باشد ، هر دو حد اعمال می شود.
پردازش مدل
پس از ایجاد مدل داده کاوی ، باید پردازش شود. ما در مقاله جداگانه گزینه پردازش را مورد بحث قرار خواهیم داد. با این حال ، برای لحظه ای بگذارید بگوییم ، پردازش مدل داده کاوی ، مدل داده کاوی را در SQL Server Analysis Service مستقر می کند تا کاربران نهایی بتوانند مدل داده کاوی را مصرف کنند.
پس از پردازش مدل ، به شرح زیر نمایش داده می شود.
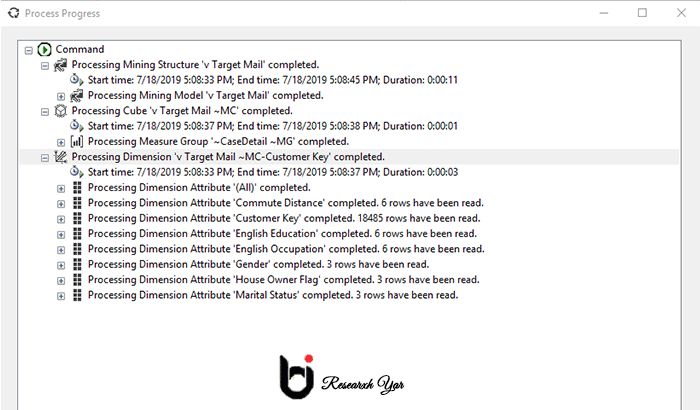
بیشتر بخوانید : هوش تجاری در مقابل داده کاوی
نماهای مدل استخراج
بعد از ایجاد مدل ، مورد بعدی تجسم مدل است. پنج زبانه برای مشاهده این مدل ها وجود دارد. ساختار معادن ، مدل های معدن ، نماهای مدل معدن ، نمودار دقت معادن و پیش بینی مدل معادن وجود دارد.
بیشتر زبانه ها مربوط به الگوریتم های داده کاوی است که قبلاً انتخاب شده بودند. بنابراین ، این بحث برای مقالات ورودی ذخیره می شود. برگه مدل استخراج برای سایر الگوریتم های استخراج معمول است.
در این تب چندین مدل استخراج وجود دارد.
همانطور که می دانیم پیش بینی می تواند اشتباه انجام شود. با این حال ، باید بدانیم که سطح دقت مدل داده کاوی که ارائه می دهیم چقدر است. نمودار دقت ، گزینه های مختلفی را برای اندازه گیری صحت مدلی که ساخته اید ، در اختیار شما قرار می دهد که در مقاله ای جداگانه مورد بحث قرار خواهد گرفت.
دوره های مرتبط
دوره کامل تضمینی هوش تجاری با رویکرد کسب درآمد در داخل و خارج از کشور
آنالیز داده و هوش تجاری یکی از پردرآمدهای شغل های دنیا چه در داخل کشور و چه خارج از کشور است. ما در دوره آموزشی صفر تا صد هوش تجاری را به صورت تضمینی آموزش میدهیم.

آموزش ویدیویی هوش تجاری در SQL
شما در این دوره آموزشی با مفاهیم و اصول هوش تجاری در SQL آشنا می شوید و متوجه می شوید که برای ساخت یک داشبورد در هر نرم افزاری نیاز به چه مراحل و اصول و پایه هایی دارید همچنین با سیستم های هوش تجاری بزرگ آشنا شده و خود را برای تحلیل طراحی و پیاده سازی یک سامانه هوش تجاری آماده می کنید.

دوره کامل مقدماتی آموزش هوش تجاری
شما در این دوره آموزشی (دوره کامل مقدماتی آموزش هوش تجاری) با مفاهیم و مقدمات هوش تجاری در SQL آشنا می شوید و متوجه می شوید که برای ساخت یک داشبورد در هر نرم افزاری نیاز به چه مراحل و اصول و پایه هایی دارید همچنین با سیستم های هوش تجاری بزرگ آشنا شده و خود را برای تحلیل طراحی و پیاده سازی یک سامانه هوش تجاری آماده می کنید.

دیدگاهتان را بنویسید