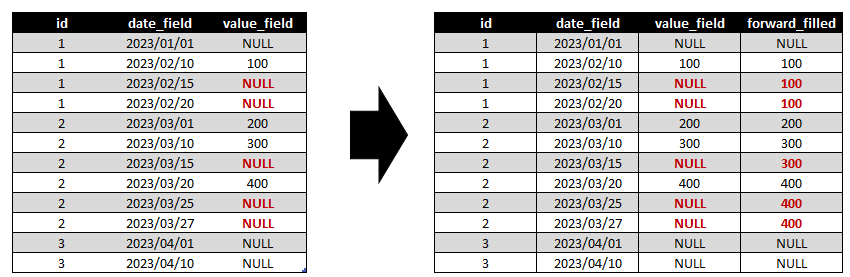
در این مقاله قراره به بررسی روش هایی برای پر کردن NULL های موجود با استفاده از مقادیر پیشین بپردازیم. داده هایی مثل موجودی یا لاگ ها و حتی خروجی های crawl که گپ هایی رو بوجود می آورند. که یکی از دلایل ایجاد این موضوع، میتونه مشابه بودن مقادیر با مقادیر پیشین باشه. و البته در محاسبات و حتی ایجاد روند ( trend) هم محدودیت ایجاد می کنند. به منظور شرح بهتر مساله به تصویر قبل و بعد تغییرات آورده شده در زیر دقت کنید:
و اما بریم سراغ راه حل ها! در این مقاله به بررسی 3 روش می پردازیم که به ترتیب روش بعدی از روش قبلی performance بهتری داره. اگر برای حجم داده زیاد می خواهید این کار رو انجام بدید که بهتره از روش سوم استفاده کنید البته باز با توجه به نوع داده تست هم داشته باشید.
داده های مثال:
console.log( 'Code is Poetry' );DROP TABLE IF EXISTS #demo_data CREATE TABLE #demo_data ( id INT ,date_field DATE ,value_field INT ) INSERT INTO #demo_data VALUES (1, '2023-01-01', NULL) ,(1, '2023-02-10', 100) ,(1, '2023-02-15', NULL) ,(1, '2023-02-20', NULL) ,(2, '2023-03-01', 200) ,(2, '2023-03-10', 300) ,(2, '2023-03-15', NULL) ,(2, '2023-03-20', 400) ,(2, '2023-03-25', NULL) ,(2, '2023-03-27', NULL) ,(3, '2023-04-01', NULL) ,(3, '2023-04-10', NULL) SELECT * FROM #demo_data
روش اول : استفاده از SUBQUERY
در این روش با استفاده از subquery مقدار top 1 مقداری که از تاریخ و شناسه اون سطر کوچکتر باشه رو پیدا می کنیم و برای هر سطر باز میگردونیم. البته این کار رو فقط برای مقادیر NULL انجام میدیم. کد نهایی به صورت زیر:
روش دوم : استفاده از OUTERAPPLY
البته اگر با apply ها آشنا باشید احتمالا حدس زدید که کوئری بالا رو هم با apply هم میشه انجام داد. تفاوت چندانی از نظر script در این دو روش وجود نداره به غیر از این که در روش قبل از CASE برای پیدا کردن NULL ها استفاده می شد اما در این روش تنها مقدار تاریخ رو به جای کوچکتر به صورت کوچکتر مساوی می نویسیم. کد نهایی به صورت زیر:
console.log( 'Code is Poetry' );
SELECT * FROM #demo_data OUTER APPLY ( SELECT TOP 1 inner_table.value_field as forward_filled FROM #demo_data as inner_table WHERE inner_table.id = #demo_data.id AND inner_table.date_field <= #demo_data.date_field AND inner_table.value_field IS NOT NULL ORDER BY inner_table.date_field DESC ) as first_non_null
روش سوم : استفاده از WINDOW FUNCTIONS
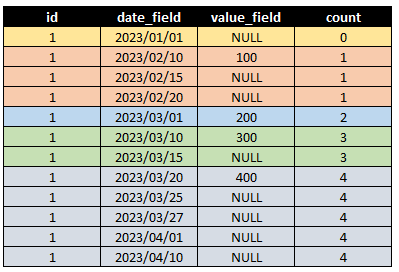
و اما روش آخر که کد پیچیده تری در ظاهر داره ولی از طرفی سرعت بهتری هم داره. در این روش ابتدا تعداد همه مقادیر (که NULL هم نیستند) رو میشمریم. یعنی به هر سطری که رسیدیم برای هر id مشخص می کنیم چه تعداد مقدار غیر NULL وجود داره. برای این که واضح تر بشه همه id های مثال رو به یک تبدیل می کنم تا دقیق تر بتونیم بررسیش کنیم.
با توجه به تصویر بالا برای id شماره 1 چهار عدد غیر NULL داریم.به طور مثال در id شماره 1 مقدار 200، عدد دوم هستش. از این ستون جدید به منظور گروه بندی استفاده می کنیم. این گروه بندی نیز برای بدست آوردن بیشترین مقدار در گروه استفاده می شود. در حقیقت به این صورت اولین مقدار غیر NULL و به تمام مقادیر NULL بعدش یه کد دادیم.
و اما کد نهایی به صورت زیر خواهد بود:
console.log( 'Code is Poetry' );
SELECT id ,date_field ,value_field ,MAX(value_field) OVER (PARTITION BY id, count_of_not_nulls) as forward_filled FROM ( SELECT id ,date_field ,value_field ,COUNT(value_field) OVER (PARTITION BY id ORDER BY date_field) as count_of_not_nulls FROM #demo_data ) as grouped ORDER BY id ,date_field
آموزش کامل و پروژه محور مباحث به همراه مثال کاملا عملی در محیط سی شارپ که یک محیط برنامه نویسی ماکروسافتی می باشد. دوره آموزش داشبورد سازی در سی شارپ شامل ساخت یک داشبود زیبا در محیط سی شارپ به کمک کامپوننتهای ssrs و Chart.js می باشد.
آموزش ویدیویی هوش تجاری در Oracle ابتدا به بررسی ساختار کلی هوش تجاری اوراکل پرداخته و سپس به مراحل نصب نرم افزارهای مرتبط با کار خود می پردازیم. سپس مباحث آنالیز داده و فاندامنتال کار را بررسی کرده و در خصوص ریپازیتوری و مسایل مربوط به ان صحبت می کنیم.
دوره کامل تضمینی هوش تجاری با رویکرد کسب درآمد در داخل و خارج از کشور
آنالیز داده و هوش تجاری یکی از پردرآمدهای شغل های دنیا چه در داخل کشور و چه خارج از کشور است. ما در دوره آموزشی صفر تا صد هوش تجاری را به صورت تضمینی آموزش میدهیم.





دیدگاهتان را بنویسید