داده کاوی در SSAS

SQL Server با ارائه داده کاوی در خدمات تجزیه و تحلیل از سال 2000 پیشرو در تجزیه و تحلیل پیش بینی بوده است. ترکیبی از خدمات ادغام ، خدمات گزارش دهی و SQL Server Data Mining یک بستر یکپارچه برای تجزیه و تحلیل پیش بینی کننده است که شامل پاکسازی و آماده سازی داده ها ، یادگیری ماشین و گزارش می شود. داده کاوی SQL Server شامل الگوریتم های استاندارد متعددی از جمله مدل های خوشه بندی EM و K-means ، شبکه های عصبی ، رگرسیون لجستیک و رگرسیون خطی ، درختان تصمیم گیری و طبقه بندی کننده های ساده است. همه مدل ها دارای تجسم های یکپارچه هستند تا به شما در توسعه ، اصلاح و ارزیابی مدل های شما کمک کنند. ادغام داده کاوی در هوش تجاری به شما کمک می کند تا تصمیمات هوشمندانه ای در مورد مشکلات پیچیده بگیرید.
مزایای داده کاوی در SSAS
داده کاوی (که به آن تجزیه و تحلیل پیش بینی و یادگیری ماشینی نیز گفته می شود) از اصول آماری برای کشف الگوهای داده های شما استفاده می کند. با استفاده از الگوریتم های داده کاوی در خدمات تجزیه و تحلیل بر روی داده های خود ، می توانید روندها را پیش بینی کنید ، الگوها را مشخص کنید ، قوانین و توصیه هایی ایجاد کنید ، توالی رویدادها را در مجموعه داده های پیچیده تجزیه و تحلیل کنید و بینش جدیدی کسب کنید.
در SQL Server 2017 ، داده کاوی قدرتمند ، قابل دسترسی و یکپارچه با ابزارهایی است که بسیاری از مردم ترجیح می دهند از آن ها برای تجزیه و تحلیل و گزارش دهی استفاده کنند.
ویژگی های کلیدی داده کاوی در SSAS
SQL Server Data Mining ویژگی های زیر را در پشتیبانی از راه حل های داده کاوی یکپارچه ارائه می دهد:
- دیتاسورس های چندگانه
می توانید از هر منبع داده ای برای داده کاوی ، از جمله excel و فایل های متنی استفاده کنید. همچنین می توانید از کیوب های OLAP ایجاد شده در Analysis Services به راحتی کوئری بگیرید. با این حال ، شما نمی توانید از داده های یک پایگاه داده in memory استفاده کنید.
- پاکسازی یکپارچه داده ها ، مدیریت داده ها و گزارش
خدمات یکپارچه سازی یا data integration ابزارهایی را برای پاکسازی داده ها فراهم می کند. شما می توانید فرآیندهای ETL را برای پاکسازی داده برای مدل سازی ایجاد کنید.
- الگوریتم های متعدد قابل تنظیم
علاوه بر ارائه الگوریتم هایی مانند خوشه بندی ، شبکه های عصبی و درختان تصمیم گیری ، SQL Server Data Mining از توسعه الگوریتم های پلاگین سفارشی شما پشتیبانی می کند.
- زیرساخت تست مدل
می توانید از هر منبع داده ای برای داده کاوی ، از جمله excel و فایل های متنی استفاده کنید. همچنین می توانید از کیوب های OLAP ایجاد شده در Analysis Services به راحتی کوئری بگیرید. با این حال ، شما نمی توانید از داده های یک پایگاه داده in memory استفاده کنید.
- کوئری و قابلیت دریل
SQL Server Data Mining زبان DMX را برای ادغام نمایش داده های پیش بینی در برنامه ها فراهم می کند. همچنین می توانید آمار و الگوهای دقیق را از مدل ها بازیابی کرده و در داده ها دریل کنید.
- ابزارهای مشتری
علاوه بر استودیوهای توسعه و طراحی ارائه شده توسط SQL Server ، می توانید از افزونه های Data Mining for Excel برای ایجاد ، پرس و جو و استفاده از مدل ها استفاده کنید. یا ، مشتری های سفارشی ، از جمله خدمات وب ایجاد کنید.
- پشتیبانی از زبان برنامه نویسی و API مدیریت شده
همه اشیاء داده کاوی کاملاً قابل برنامه ریزی هستند. برنامه نویسی از طریق MDX ، XMLA یا افزونه های PowerShell برای خدمات تجزیه و تحلیل امکان پذیر است. برای پرس و جو و اسکریپت نویسی از زبان Data Mining Extensions (DMX) استفاده کنید.
- امنیت و استقرار
از طریق خدمات تجزیه و تحلیل ، امنیت مبتنی بر نقش را ارائه می دهد ، از جمله مجوزهای جداگانه برای آموزش در مدل سازی و ساختار داده ها. استقرار آسان مدل ها در سرورهای دیگر ، به طوری که کاربران می توانند به الگوها دسترسی داشته باشند و در آنها دریل کنند یا پیش بینی ها را انجام دهند

مفاهیم داده کاوی مورد نیاز در SSAS
داده کاوی فرایند کشف اطلاعات قابل اجرا از مجموعه داده های بزرگ است. داده کاوی از تحلیل ریاضی برای استخراج الگوها و روندهایی که در داده ها وجود دارد استفاده می کند. به طور معمول ، این الگوها با اکتشاف داده های به صورت ساده قابل کشف نیستند زیرا روابط بسیار پیچیده هستند یا داده های زیادی وجود دارد.
این الگوها و روندها را می توان به عنوان یک مدل داده کاوی جمع آوری و تعریف کرد . مدل های داده کاوی را می توان در سناریوهای خاصی مانند موارد زیر اعمال کرد:
- پیش بینی : برآورد فروش ، پیش بینی بار سرور یا خرابی سرور
- ریسک و احتمال : انتخاب بهترین مشتریان برای ارسال های هدفمند ، تعیین نقطه سر به سر احتمالی برای سناریوهای خطر ، اختصاص احتمال به تشخیص ها یا سایر نتایج
- توصیه ها : تعیین اینکه کدام محصولات به احتمال زیاد با هم فروخته می شوند ، تولید توصیه می شود
- یافتن دنباله ها : تجزیه و تحلیل انتخاب های مشتری در سبد خرید ، پیش بینی رویدادهای احتمالی بعدی
- گروه بندی : تفکیک مشتریان یا رویدادها به صورت مجموعه ای از اقلام مرتبط ، تجزیه و تحلیل و پیش بینی شباهت و نزدیکی آن ها
ایجاد یک مدل بخشی از یک فرایند بزرگتر است که شامل همه چیز از پرسیدن سوالات در مورد داده ها و ایجاد مدلی برای پاسخ به این سوالات ، و استقرار مدل در محیط کار است. این فرایند را می توان با استفاده از شش مرحله اساسی زیر تعریف کرد:
- تعریف مسئله
- آماده سازی داده ها یا data preparation
- کاوش در داده ها یا exploring data
- مدلسازی داده ها
- بررسی و اعتبارسنجی مدل ها
- استقرار و به روز رسانی مدل ها
مایکروسافت SQL Server Data Mining یک محیط یکپارچه برای ایجاد و کار با مدل های داده کاوی فراهم می کند. این محیط شامل SQL Server Development Studio است که شامل الگوریتم های داده کاوی و ابزارهای پرس و جو است که ساخت راه حل جامع برای پروژه های مختلف را آسان می کند و SQL Server Management Studio ، که شامل ابزارهایی برای مرور مدل ها و مدیریت اشیاء داده کاوی است.
برای داده کاوی معمولاً با یک مجموعه داده بسیار بزرگ کار می کنید و نمی توانید هر تراکنش را از نظر کیفیت داده بررسی کنید. بنابراین ، ممکن است لازم باشد از نوعی پروفایل داده و ابزارهای تصفیه و فیلتر خودکار داده ها مانند سرویس های داده اصلی Microsoft SQL Server 2012 با نام master data service یا خدمات کیفیت داده SQL Server یا data quality service برای کاوش داده ها و یافتن ناهماهنگی ها استفاده کنید.
توجه به این نکته ضروری است که داده هایی که برای داده کاوی استفاده می کنید نیازی به ذخیره در کیوب های پردازش تحلیلی آنلاین (OLAP) یا حتی در پایگاه داده های رابطه ای نیستند ، اگرچه می توانید از هر دوی اینها به عنوان دیتاسورس استفاده کنید. شما می توانید داده کاوی را با استفاده از هر دیتاسورسی که به عنوان دیتاسورس خدمات تجزیه و تحلیل تعریف شده است انجام دهید. این ها می توانند شامل فایل های متنی ، فایل های Excel یا داده های سایر دیتاسورس های خارجی باشند

مدلسازی داده ها در SSAS
یکی از مراحل مهم در فرآیند داده کاوی ،ساختن مدل یا مدل سازی است. شما می توانید از دانش به دست آمده به کمک بررسی داده ها کمک گرفته و به کمک آن مدل های خود را بسازید.
شما ستون های داده ای را که می خواهید با ایجاد یک MiningSructure استفاده کنید ، تعریف می کنید. Mining Structure ها به منابع داده ای متصل می شوند، اما تا زمانی که آن را پردازش نکنید ، در واقع هیچ داده ای ندارد. هنگامی که Mining Structure را پردازش می کنید ، Analysis Services شروع به ساخت Aggregation ها و دیگر اطلاعات آماری می کند که می تواند برای آنالیز داده استفاده شود. این اطلاعات می تواند توسط هر مدل ماینینگی که بر اساس استراکچر یا ساختار است استفاده شود.
قبل از پردازش ساختار و مدل ، یک مدل داده کاوی نیز فقط محفظه ای است که ستون های مورد استفاده برای ورودی ، ویژگی پیش بینی شده و پارامترهایی را که به الگوریتم پردازش داده ها فید داده شده است را مشخص می کند. پردازش یک مدل اغلب آموزش یا Train نامیده می شود . آموزش به فرایند استفاده از الگوریتم ریاضی خاص برای داده های موجود در ساختار به منظور استخراج الگوها اشاره دارد. الگوهایی که در فرایند آموزش پیدا می کنید بستگی به انتخاب داده های آموزشی ، الگوریتم انتخاب شده و نحوه پیکربندی الگوریتم دارد. SQL Server 2017 شامل الگوریتم های متفاوتی است که هرکدام برای انواع مختلف کار مناسب هستند و هر کدام مدل متفاوتی را ایجاد می کنند.
با استفاده از Data Mining Wizard در SQL Server Data Tools یا با استفاده از زبان Data Mining Extensions (DMX) می توانید یک مدل جدید تعریف کنید.
مهم است که به خاطر داشته باشید که هر زمان که داده ها تغییر می کنند ، باید Mining Structure ها و mining model را به روز کنید. هنگامی که یک Mining Structure را با پردازش مجدد یا ریپراسس آن به روز می کنید ، SSAS را از منبع ، شامل هر گونه داده جدید در صورت به روز رسانی دینامیک، بازیابی می کند و Mining Structure را مجدداً مورد استفاده قرار می دهد. اگر مدلهایی دارید که بر اساس Structure هستند ، می توانید مدلهایی را که بر اساس Structure هستند به روز کنید ، به این معنی که آنها بر روی داده های جدید دوباره ترین می شوند.
Mining Structure یا ساختار های داده کاوی
Mining structure داده هایی که Mining model ها از آنها ساخته شده اند ، شامل موارد زیر می شود:
DSV یا DataSourceView ، تعداد و نوع ستون ها و یک پارتیشن اختیاری را در مجموعه های آموزشی و تست مشخص می کند. یک Mining Structure واحد می تواند از چندین Mining Model که دامنه یکسانی دارند پشتیبانی کند. نمودار زیر رابطه ساختار داده کاوی با DataSource ها و مدل های داده کاوی تشکیل دهنده آن را نشان می دهد.
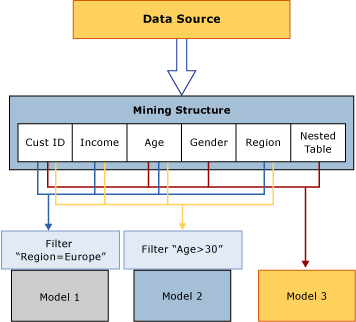
Mining Structure در نمودار بر اساس یک دیتاسورس است که شامل چندین جدول یا ویو است ، که در قسمت CustomerID به هم متصل شده اند. یک جدول حاوی اطلاعاتی درباره مشتریان ، مانند منطقه جغرافیایی ، سن ، درآمد و جنسیت است ، در حالی که جدول تو در تو مربوط شامل چندین ردیف اطلاعات اضافی در مورد هر مشتری ، مانند محصولاتی است که مشتری خریداری کرده است. نمودار نشان می دهد که چندین مدل را می توان بر روی یک Mining Structure ساخت و مدل ها می توانند از ستون های مختلف ساختار استفاده کنند.
مدل 1 از CustomerID ، درآمد ، سن ، منطقه استفاده می کند و داده های منطقه را فیلتر می کند.
مدل 2 از CustomerID ، درآمد ، سن ، منطقه استفاده می کند و داده ها را بر اساس سن فیلتر می کند.
مدل 3 از CustomerID ، سن ، جنسیت و جدول تو در تو استفاده می کند ، بدون فیلتر.
از آنجا که مدل ها از ستون های مختلف برای ورودی استفاده می کنند ، و از آنجا که دو مدل با استفاده از فیلتر ، داده های مورد استفاده در مدل را محدود می کنند ، ممکن است نتایج بسیار متفاوتی داشته باشند ، هرچند بر اساس داده های یکسان باشند. توجه داشته باشید که ستون CustomerID در همه مدل ها مورد نیاز است زیرا تنها ستون موجود است که می تواند به عنوان کلید مورد استفاده شود.
تعریف یک Mining Structure
- دیتاسورس را تعریف کنید.
- ستون هایی از داده ها را انتخاب کنید (همه ستون ها نیازی به اضافه شدن به مدل ندارند) و یک کلید تعریف کنید.
- در صورت وجود ، کلیدی برای Structure تعریف کنید.بهترین کلید همان کلید جدول می باشد.
- مشخص کنید که آیا دیتاسورس باید در مجموعه Train و مجموعه Testجدا شوند یا خیر. این مرحله اختیاری است.
- Mining Structure را پردازش کنید.
دیتاسورس برای Mining Structure ها
هنگام تعریف Mining Structure ، از ستون هایی استفاده می کنید که در DSV موجود است. منابع داده اصلی برای برنامه های سرویس گیرنده قابل مشاهده نیستند و می توانید از ویژگی های DSV برای اصلاح انواع داده ها ، ایجاد مجموعه ها یا ستون های مستعار استفاده کنید.
اگر چندین Mining Model را از یک Mining Structure یکسان بسازید ، مدل ها می توانند از ستون های مختلف Structure استفاده کنند. به عنوان مثال ، می توانید یک Structure واحد ایجاد کنید و سپس درخت تصمیم گیری جداگانه و مدل های خوشه ای از آن بسازید ، با هر مدل از ستون های مختلف و پیش بینی ویژگی های مختلف.
علاوه بر این ، هر مدل می تواند از ستون های ساختار به روش های مختلف استفاده کند. به عنوان مثال ، نمای منبع داده شما یا DSV ممکن است دارای یک ستون درآمد باشد که می توانید آن را به روش های مختلف برای مدل های مختلف قرار دهید.
علاوه بر این ، هر مدل Mining structure به روش های مختلفی مورد استفاده قرار میگیرد. به عنوان مثال ، نمای منبع داده شما ممکن است دارای یک ستون درآمد یا فروش یا هر چیزی باشد که می توانید آن را به روش های مختلف برای مدل های مختلف قرار دهید.
ستون های Mining Structure
اجزای Mining Structureها ، ستون هایی هستند که داده هایی را که دیتاسورس شامل آن ها است مشخص می کنند. این ستون ها حاوی اطلاعاتی مانند نوع داده ، نوع محتوا و نحوه توزیع داده ها هستند. Mining Structure ها حاوی اطلاعاتی در مورد نحوه استفاده از ستون ها برای یک مدل خاص mining یا نوع الگوریتم مورد استفاده برای ساخت مدل نیست. این اطلاعات در خود مدل تعریف شده است.
یک ساختار استخراج نیز می تواند شامل جداول تو در تو باشد. جدول تو در تو نشان دهنده رابطه یک به یک انتیتی و ویژگی های مربوط به آن است. به عنوان مثال ، اگر اطلاعاتی که مشتری را توصیف می کند در یک جدول قرار دارد و خریدهای مشتری در یک جدول دیگر قرار دارد ، می توانید از جداول تو در تو استفاده کنید تا اطلاعات را در یک مورد یکسان ترکیب کنید. شناسه مشتری نهاد مربوطه است و خریدها ویژگی های مرتبط هستند.
برای ایجاد یک مدل داده کاوی در SQL Server Data Tools ، ابتدا باید یک Mining Structute ایجاد کنید. از ویزاردهای Data Mining هم میتوانید استفاده کنید.
اگر با استفاده از Data Mining Extensions (DMX) یک مدل ماینینگ ایجاد می کنید ، می توانید مدل و ستون های موجود در آن را مشخص کنید و DMX به طور خودکار ساختار ماینینگ مورد نیاز را ایجاد می کند.
تقسیم داده ها به مجموعه های آموزشی و آزمایشی
وقتی داده ها را برای ساخت یک Mining Structure تعریف می کنید ، می توانید مشخص می کنید که برخی از داده ها برای آموزش و برخی برای آزمایش استفاده شوند. بنابراین ، دیگر لازم نیست داده های خود را پیش از ایجاد ساختار داده کاوی جدا کنید. در عوض ، در حالی که مدل خود را ایجاد می کنید ، می توانید تعیین کنید که درصد خاصی از داده ها برای آزمایش و بقیه برای آموزش استفاده شوند ، یا می توانید تعداد مشخصی از موارد را برای استفاده به عنوان مجموعه داده های آزمایش مشخص کنید. اطلاعات مربوط به مجموعه داده های آموزش و آزمایش با Mining Structure ذخیره می شود و در نتیجه ، مجموعه آزمایش یکسانی را می توان با همه مدل هایی که بر اساس آن ساختار هستند استفاده کرد.
فعال کردن Drillthrough
حتی اگر قصد استفاده از ستون را در مدل خاص ندارید ، می توانید ستون هایی را به ساختار استخراج اضافه کنید. برای مثال ، اگر می خواهید آدرس های ایمیل مشتریان را در یک مدل خوشه بندی بازیابی کنید برای نادیده گرفتن یک ستون در مرحله تجزیه و تحلیل و پیش بینی ، آن را به ساختار اضافه می کنید اما استفاده از ستون را مشخص نمی کنید ، یا تیک استفاده را روی Ignore قرار می دهید. اگر drillthrough در مدل Mining Structure فعال شده است و اگر مجوزهای مناسب را دارید ، داده های تیک گذاری شده به این روش هنوز می توانند در کوئری استفاده شوند. به عنوان مثال ، می توانید خوشه های حاصل از تجزیه و تحلیل همه مشتریان را بررسی کنید ، و سپس از یک پرس و جو برای یافتن نام و آدرس ایمیل مشتریان در یک خوشه خاص استفاده کنید.
پراسس استراکچرهای ماینینگ
یک ساختار ماینینگ تا زمانی که پردازش نشود فقط یک ظرف خالی است. هنگامی که یک ساختار استخراج را پردازش می کنید ، Analysis Services یک حافظه پنهان ایجاد می کند که آمار مربوط به داده ها ، اطلاعاتی در مورد چگونگی تفکیک ویژگی های پیوسته و سایر اطلاعاتی که بعداً توسط مدلهای استراکچر مورد استفاده قرار می گیرد ، ذخیره می کند. مدل استراکچر خود این اطلاعات خلاصه را ذخیره نمی کند ، بلکه اطلاعاتی را که هنگام پردازش استراکچر ماینینگ ذخیره می شد ، ارجاع می دهد. بنابراین ، نیازی به پردازش مجدد ساختار در هر بار افزودن یک مدل جدید به ساختار موجود ندارید. فقط می توانید مدل را پراسس کنید.
اگر حافظه پنهان بسیار بزرگ است یا می خواهید داده های تمپ را حذف کنید ، می توانید پس از پردازش این حافظه را کنار بگذارید. اگر نمی خواهید داده ها ذخیره شوند ، می توانید ویژگی CacheMode ساختار استخراج را به ClearAfterProcessing تغییر دهید . این کار حافظه کش را پس از پردازش هر مدل از بین می برد. با تنظیم ویژگی CacheMode روی ClearAfterProcessing ، drillthrough از مدل استراکچر غیرفعال می شود.
با این حال ، پس از دیسپوز حافظه نهان ، نمی توانید مدل های جدیدی را به ساختار استراکچر داده کاوی خود اضافه کنید. اگر یک مدل استراکچر جدید به مدل خود اضافه کنید یا ویژگی های مدل های موجود را تغییر دهید ، ابتدا باید ساختار استخراج را مجددا پراسس کنید.
مشاهده ساختارهای ماینینگ یا Mining Structure
شما نمی توانید از یوزرهای خود برای اکسپلور داده ها استفاده کنید. با این حال ، در SQL Server Data Tools ، می توانید از برگه Mining Structure در Data Mining Designer برای مشاهده ستون های Mining Structute و تعاریف آن ها استفاده کنید.
اگر می خواهید داده ها را در مدلی که ساختید مرور کنید ، می توانید با استفاده از Extensions Data Mining (DMX) پرس و جو ایجاد کنید. به عنوان مثال ، دستور SELECT * FROM .CASES تمام داده های موجود در ساختار استخراج را برمی گرداند. برای بازیابی این اطلاعات ، ساختار استخراج باید پردازش شده و نتایج پردازش باید در حافظه پنهان ذخیره شود.
دستور SELECT * FROM .CASES همان ستون ها را برمی گرداند ، اما فقط برای موارد مربوط به آن مدل خاص.
بطور کلی دیتاماینینگ به دو بخش زیر تقسیم میشود:
- اهداف توصیفی (Descriptive Goal)
بدنبال یافتن پترنها و روابط بین دیتا هستیم، بدین ترتیب مدلی برای توصیف بهتر دیتا بدست خواهد آمد.
- اهداف پیش بینانه (Predictive Goal)
بدنبال انجام پردیکشن با استفاده از پترنها و مدلهای فوق هستیم.
مراحل اجرای یک پروژه دیتاماینینگ شامل مراحل زیر است
- آنالیز: مهمترین فعالیت در این فاز، فهم عمیق مسئله و شناخت درست مسئله و شناسائی مفاهیم کلیدی (Key Concept) در مسئله است.
- طراحی: مهمترین فعالیت این فاز، فرموله کردن مسئله با استفاده از مفاهیم کلیدی است.
- پیاده سازی/ نگهداری و بهبود
مراحل کاری دیتاماینینگ بر اساس استاندارد CRISPDM
محصول مشترک شرکتهای SPSS, Teradata, NCR و دایملر کرایسلر است و یک فرآیند استاندارد CrossIndustry برای دیتاماینینگ است که به طور گسترده ای استفاده میشود.
مراحل کاری در این مدل به شش فاز اصلی به شرح زیر تقسیم میشوند:
- درک پروژه و فهم حوزه کاربرد (Business Understanding)
به طور صریح و آشکار اهداف و نیازمندیها مشخص میشود. ترجمه اهداف و محدودیت آن در قاعده سازی، تعریف مسئله دیتاماینینگ و مهیا کردن استراتژی اولیه برای نائل شدن به اهداف در این مرحله تعریف می شود.
- انتخاب دیتا (Data Understanding)
این مرحله شامل جمع آوری دیتا برای استفاده از آنالیز اکتشافی و مشخص کردن اطلاعات اولیه برای ارزیابی دیتای با کیفیت و انتخاب دیتای مفید و مورد نیاز میباشد.
- آماده سازی دیتا (Data Preparation)
آماده کردن دیتای اولیه خام به دیتای نهایی، این دادها در کلیه مراحل بعدی استفاده میشود و از این نظر این مرحله آنالیز و تلاش بیشتری را میطلبد. انتخاب عناصر و شناسههای آنالیز شده را برای استخراج دیتا اختصاص میدهیم و با تمیز کردن دیتای خام آن را برای ابزارهای مدلینگ آماده می کنیم.
- مدلینگ (Modeling)
با انتخاب و به کار بستن تکنیکهای مدلینگ مناسب و روش دیتاماینینگ معین نتایج مدلینگ را بهینه می کنیم، که در صورت نیاز میتوانیم با برگشت به عقب آنالیز مدلینگ را بهینهتر نماییم.
- ارزیابی (Evaluation)
مشخص کردن اینکه آیا مدل انتخابی، ما را به اهدافمان که در اولین مرحله تعیین کردیم، می رساند. اتخاذ تصمیم راجع به استفاده از نتایج دیتاماینینگ برای اعتبارسنجی نیز در این مرحله انجام می شود.
- استقرار (Deployment)
استفاده کردن از مدل ایجاد شده، برای مثال میتواند تولید یک گزارش ساده از خروجیها را نام برد، و برای یک مثال پیچیده تکمیل کردن پردازش دیتاماینینگ موازی در سایر حوزهها میباشد، که این پترنها به یک دانش مفید و قابل استفاده تبدیل میشوند و پس از بهبود آنها، پترنهایی که کارا محسوب می شوند در یک سیستم اجرایی به کار گرفته خواهند شد.
مراحل کاری دیتاماینینگ در بستر تکنولوژی مایکروسافت
دیتاماینینگ غالباً به عنوان فرآیند استخراج اطلاعات، پترن ها و ترندهای موجود در مجموعه ی عظیمی از دیتا یاد می شود. این پترن ها و ترندها را می توان به عنوان یک Mining Structureی تعریف نمود. به بیانی دیگر ایجاد یک Mining Structureی بخشی از فرآیند بزرگتری است که در برگیرنده ی همه مراحل؛ از تعریف مسئله که مدل حل خواهد نمود تا اجرای مدل در محیطهای کاری است.
می توان این فرآیند را با استفاده از 6 مرحله اساسی زیر تعریف نمود:
باید در نظر داشت که تهیه یک مدل دیتاماینینگ، فرآیندی چرخشی، پویا و تکرار پذیر می باشد و ممکن است هر یک از این مراحل آن قدر تکرار شود، تا مدل مناسبی تهیه گردد.
- تعریف مسئله (Defining the Problem)
تعریف روشنی از مشکل و مسئله کسب و کار است. این مرحله شامل تجزیه و آنالیز نیازمندیهای کسب وکار، تعریف دامنه مشکل، تعریف معیارهایی که با آن مدلها ارزیابی خواهد شد و تعریف هدف نهایی پروژه ی دیتاماینینگ است.
- آماده سازی دیتا (Preparing Data)
یکپارچه سازی و پالایش داده هایی است که در مرحله ی تعریف مسئله فرآیند معین شده است. SQL SERVER INTEGRATION SERVICE حاوی تمامی ابزارهای ملزوم برای تکمیل این مرحله میباشد.
- بررسی دیتا (Exploring Data)
به منظور تصمیم گیریهای مناسب در هنگام تهیه مدل، می بایست دیتا را درک نمود و پس از آن می توان تصمیم گیری در مورد وجود دیتای مخدوش در مجموعه داده و در نهایت استراتژی مناسب برای رفع این مشکلات اتخاذ نمود. DSV Designer موجود در SSDT حاوی ابزارهای جامعی برای بررسی و شناخت دیتا شامل محاسبه ارقام حداقل و حداکثر، محاسبه میانگین و انحراف معیار و بررسی توزیع دیتا می باشد.
- تهیه مدل ها (Building Models)
پیش از تهیه مدل باید، دیتا را به دو دسته ی دیتای Train و اعتبارسنجی (Test) تقسیم نمود. از دیتای Train برای تهیه مدل و از دیتای اعتبارسنجی برای آزمایش صحت مدل با ایجاد سوالاتی در مورد صحت پردیکشنها استفاده نمود. پس از تعریف Mining Structure، می بایست به پردازش مدل پرداخته شود و ساختارهای خالی با پترن هایی که مدل را توصیف می نمایند، پُر شوند. این مرحله با عنوان آموزش مدل شناخته می شود.
- بررسی و ارزیابی مدلها (Exploring and Validating Models)
این مرحله شامل بررسی مدلهای ایجاد شده به منظور آزمودن Performance آنهاست. می توان مدلها را با ابزارهای موجود در Designer از جمله نمودار صعود و یا ماتریس دسته بندی بررسی نمود.
- اجرا و بروزرسانی مدلها (Deploying and Updating Models)
این مرحله شامل اجرای مدل هایی است که بهترین کارائی را در یک محیط عملیاتی داشته اند. پس از استقرار مدلهای استخراجی در یک محیط عملیاتی می توان از این مدل ها برای پردیکشن هایی بهره گرفت.
مراحل ساخت یک Mining Structure
- ایجاد Mining Structures
تعریف یک Mining Structure شامل، تعیین تعداد ستونهای ورودی، تعداد ستونهای قابل پردیکشن و پترن ریتم وابسته به آن میباشد. Mining Structure یک ساختار داده ای است که محدوده ی داده هایی را که از روی آنها مدلهای استخراج ساخته می شود را تعریف می نماید.
- آموزش مدل (Model Training)
یک Mining Structureی، پترن ریتمهای استخراج را به داده هایی که Mining Structure ارائه می نماید، اعمال می کند. به بیان دیگر استفاده و کاربرد هر ستون و پترن ریتمی که برای ساخت مدل استفاده می شود را تعریف می کند، پس شامل داده منبع اصلی نیست، بلکه شامل اطلاعاتی است که توسط پترن ریتم کشف می شود. به آموزش مدل، پردازش مدل نیز گفته میشود و زمانی که یک مدل پردازش می شود داده هایی که توسط Mining Structure تعریف شده اند، از طریق پترن ریتمهای دیتاماینینگ انتخابی منتقل می شوند، پترن ریتم؛ پترن ها و ترندها را جستجو می کند و در ادامه این اطلاعات در مدل ذخیره می شوند. از این رو پس از یادگیری و آموزش مدل، پترن های بدست آمده در Mining Structure ذخیره می شوند.
- پردیکشن مدل (Prediction)
غالباً مهمترین مرحله و هدف نهایی در پروژههای دیتاماینینگ است. پردیکشن به کشف اطلاعات ناشناخته با استفاده از پترن های یافته شده از هیستوری دیتا اشاره دارد. در پردیکشن به یک Mining Structureی ترین شده و یک مجموعه داده ی جدید نیاز است و در طول پردیکشن موتور دیتاماینینگ، قواعد بدست آمده در مرحله یادگیری را در مورد مجموعه داده ی جدید بکار می برد و نتایج پردیکشن را به هر Case ورودی تخصیص می دهد.
زبان DMX
زبان (DMX (Data Mining eXtensions که به منظور انجام عملیات دیتاماینینگ توسط شرکت ماکروسافت ایجاد شده است بیشتر آشنا می شویم.
برای بسیاری دیتاماینینگ تنها مجموعه ای از تعدادی پترن ریتم تعبیر میشود؛ به همان طریقی که در گذشته تصورشان از دیتابیس تنها ساختاری سلسله مراتبی به منظور ذخیره دیتا بود. بدین ترتیب دیتاماینینگ به ابزاری تبدیل شده که تنها در انحصار تعدادی متخصص قرار دارد که آشنائی با اصطلاحات یک زمینه خاص را دارند. هدف از ایجاد زبان DMX تعریف مفاهیمی استاندارد و گزارهایی متداول است که در دنیای دیتاماینینگ استفاده میشود به شکلی که زبان SQL برای دیتابیس این کار را انجام میدهد.
فرضیه اساسی در دیتاماینینگ و همچنین AI از این قرار است که تعدادی نمونه به پترن ریتم نشان داده میشود و پترن ریتم با استفاده از این نمونهها قادر است به استخراج پترن ها بپردازد. بدین ترتیب به منظور بازبینی و همچنین استنتاج از اطلاعات درباره نمونههای جدید میتواند مورد استفاده قرار گیرد.
در گام نخست اقدام به تعریف مسئله و فرموله کردن آن میکنیم که اصطلاحاً Mining Model نامیده میشود. در واقع Mining Model توصیف کننده این است که داده نمونه به چه شکل به نظر میرسد و چگونه پترن ریتم دیتاماینینگ باید دیتا را تفسیر کند. در گام بعدی به فراهم کردن نمونههای داده برای پترن ریتم میپردازیم، پترن ریتم با بهره گیری از Mining Model به طریقی که یک لنز دیتا را مرتب میکند، به بررسی دیتا و استخراج پترنها میپردازد؛ این عملیات را اصطلاحاً Training Model مینامیم. هنگامی که این عملیات به پایان رسید، بسته به اینکه چگونه آنرا انجام داده اید، میتوانید به آنالیز پترنهایی که توسط پترن ریتم از روی نمونه هایتان بدست آمده بپردازید. و در نهایت میتوانید اقدام به فراهم کردن دیتای جدید و فرموله کردن آنها، به همان طریقی که نمونهها آموزش دیده اند، به منظور انجام پردیکشن و استنتاج از اطلاعات با استفاده از پترنهای کشف شده توسط پترن ریتم پرداخت.
زبان DMX وظیفه تبدیل دیتای موجودتان (سطرها و ستونهای Tables) به دیتای مورد نیاز پترن ریتمهای دیتاماینینگ (Cases و Attributes) را دارد. به منظور انجام این تبدیل به Mining Structure و Mining Model (که در بخش اول به شرح آن پرداخته شد) نیاز است. بطور خلاصه Mining Structure صورت مسئله را توصیف میکند و Mining Model وظیفه تبدیل سطرهای داده ای به درون Caseها و انجام عملیات AI با استفاده از پترن ریتم دیتاماینینگ مشخص شده را بر عهده دارد.
مشابه زبان SQL دستورات زبان DMX نیز به محیطی جهت اجرا نیاز دارند که میتوان با استفاده از (SQL Server Management Studio (SSMS به اجرای دستورات DMX اقدام نمود. ایجاد Mining Structure (Mining Structure) و Mining Structureی (Mining Model) مشابه دستورات ایجاد Table در زبان SQL میباشد. همانطور که اشاره شد، گام اول (از سه مرحله اصلی در دیتاماینینگ) ایجاد یک Mining Structure است؛ شامل تعیین تعداد ستونهای ورودی، ستونهای قابل پردیکشن و مشخص کردن نام پترن ریتم مورد استفاده در مدل. گام دوم آموزش مدل که پردازش نیز نامیده میشود و گام سوم مرحله پردیکشن است که نیاز به یک Mining Structure آموزش دیده و مجموعه اطلاعات جدید دارد. در طول پردیکشن، موتور دیتاماینینگ قوانین (Rules) پیدا شده در مرحلهی آموزش (یادگیری) را با مجموعه اطلاعات جدید تطبیق داده و نتیجه پردیکشن را برای هر Case ورودی انجام میدهد. دو نوع Query پردیکشن وجود دارد Batch و Singleton که به ترتیب چند Case ورودی دارد و خروجی در یک جدول ذخیره میشود و دیگری تنها یک Case ورودی دارد و خروجی در زمان اجرا ساخته میشود.
- ایجاد یک Mining Structure و Mining Structure مربوط به هم و تحت یک نام، زمانی کاربرد دارد که یک Mining Structure فقط شامل یک Mining Structure باشد.
- ایجاد یک Mining Structure و سپس اضافه نمودن یک Mining Structure به ساختار تعریف شده، زمانی کاربرد دارد که یک Mining Structure شامل چندین Mining Structureی باشد. دلایل مختلفی وجود دارد که ممکن است نیاز به این روش باشد، برای مثال ممکن است مدلهای متعددی را با استفاده از پترن ریتمهای مختلف ساخت و سپس بررسی نمود که کدام مدل بهتر عمل خواهد کرد و یا مدلهای متعددی را با استفاده از یک پترن ریتم ولی با مجموعه پارامترهای متفاوت برای هر مدل ساخت و سپس بهترین را انتخاب نمود.
عناصر سازندهی Mining Structure، ستونهای Mining Structure هستند که داده هایی را که منبع اصلی داده فراهم میکند، توصیف میکند. این ستونها شامل اطلاعاتی از قبیل نوع داده (Data Type)، نوع محتوا (Content Type)، ماهیت داده و اینکه داده چگونه توزیع شده است میباشند. نوع محتوا پیوسته و یا گسسته بودن آن را مشخص میکند و بدین ترتیب به پترن ریتم راه درست مدل کردن ستون را نشان میدهیم. کلمه کلیدی Discrete برای ماهیت گسسته داده و از کلمه Continuous برای ماهیت پیوسته داده استفاده میشود.
مقادیر نوع داده و نوع محتوا به قرار زیر میباشند:
Data Type | کاربرد |
LONG | اعداد صحیح |
DOUBLE | اعداد اعشاری |
TEXT | دیتای رشته ای |
DATE | دیتای تاریخی |
BOOLEAN | دیتای منطقی (True و False) |
TABLE | برای تعریف Nested Case |
Content Type | کاربرد |
KEY | مشخص کننده کلید |
DISCRETE | دیتای گسسته |
CONTINUOUS | دیتای پیوسته |
DISCRETIZED | دیتای گسسته شده |
KEY TIME | کلید زمان، تنها در مدلهای Time Series استفاده میشود |
KEY SEQUENCE | کلید توالی، تنها در بخش Nested Table مدلهای Sequence Clustering استفاده میشود |
همچنین یک Mining Structure استفاده و کاربرد هر ستون و پترن ریتمی که برای ساخت مدل استفاده میشود را تعریف میکند، میتوانید با استفاده از کلمه کلیدی Predict و یا Predict_Only خاصیت پردیکشن را به ستونها اضافه نمود، برای نمونه به دستورات زیر توجه نمائید:
CREATE MINING STRUCTURE [New Mailing]
(
CKey LONG KEY,
Type TEXT DISCRETE,
[Number Cars Owned] LONG DISCRETE,
[Machine Buyer] LONG DISCRETE
)
GO
ALTER MINING STRUCTURE [New Mailing]
ADD MINING MODEL [KNN]
(
CKey,
Type,
[Number Cars Owned],
[Machine Buyer] PREDICT
)
USING Naive_Bayes
به منظور آموزش یک Mining Structure از دستور Insert به شکل زیر استفاده میشود:
INSERT INTO <mining model name>
[<mapped model columns>]
<source data query>
1 – Association Rules
به منظور ایجاد قوانینی که توصیف کننده این موضوع باشد که چه مواردی احتمالاً با یکدیگر در تراکنشها ظاهر میشوند، استفاده میشود.
Range | Default | Parameter |
(…,1] | 200000 | MAXIMUM_ITEMSET_COUNT |
[0,500] | 3 | MAXIMUM_ITEMSET_SIZE |
(…,0.0) | 1.0 | MAXIMUM SUPPORT |
(…,…) | 999999999- | MINIMUM IMPORTANCE |
[1,500] | 1 | MINIMUM_ITEMSET_SIZE |
[0.0,1.0] | 0.4 | MINIMUM PROBABILITY |
(…,0.0] | 0.0 | MINIMUM SUPPORT |
2 – مایکروسافت Clustering
به منظور شناسائی روابطی که در یک مجموعه داده ممکن است از طریق مشاهده منطقی به نظر نرسد، استفاده میشود. در واقع این پترن ریتم با استفاده از تکنیکهای تکرار شونده رکوردها را در خوشه هایی که حاوی ویژگیهای مشابه هستند گروه بندی میکند.
Range | Default | Parameter |
(…,0] | 10 | CLUSTER COUNT |
(…,0] | 0 | CLUSTER SEED |
1,2,3,4 | 1 | CLUSTERING METHOD |
[0,65535] | 255 | MAXIMUM_INPUT_ATTRIBUTES |
[2,65535],0 | 100 | MAXIMUM STATES |
(…,0) | 1 | MINIMUM SUPPORT |
[1,50] | 10 | MODELLING_CARDINALITY |
(…,100],0 | 50000 | SAMPLE SIZE |
(…,0) | 10 | STOPPING TOLERANCE |
3 – مایکروسافت Decision Trees
مبتنی بر روابط بین ستون های یک مجموعه داده ای باعث پردیکشن روابط مدلها میشود، که به صورت یک سری درختوار ویژگیها در آن شکسته میشوند.
به منظور انجام پردیکشن از هر دو ویژگی پیوسته و گسسته پشتیبانی میشود.
Range | Default | Parameter |
(0.0,1.0) | COMPLEXITY_PENALTY | |
FORCE REGRESSOR | ||
[0,65535] | 255 | MAXIMUM_INPUT_ATTRIBUTES |
[0,65535] | 255 | MAXIMUM_OUTPUT_ATTRIBUTES |
(…,0.0) | 10.0 | MINIMUM SUPPORT |
1,3,4 | 4 | SCORE METHOD |
[1,3] | 3 | SPLIT METHOD |
4 – مایکروسافت Linear Regression
چنانچه یک وابستگی خطی میان متغیر هدف و متغیرهای مورد بررسی وجود داشته باشد، کارآمدترین رابطه میان متغیر هدف و ورودیها را پیدا میکند.
به منظور انجام پردیکشن از ویژگی پیوسته پشتیبانی میکند.
Range | Default | Parameter |
FORCE REGRESSOR | ||
[0,65535] | 255 | MAXIMUM_INPUT_ATTRIBUTES |
[0,65535] | 255 | MAXIMUM_OUTPUT_ATTRIBUTES |
5 – مایکروسافت Logistic Regression
به منظور تجزیه و آنالیز عواملی که در یک تصمیم گیری مشارکت دارند که پی آمد آن به وقوع یا عدم وقوع یک رویداد میانجامد از این پترن ریتم استفاده میشود.
جهت انجام پردیکشن از هر دو ویژگی پیوسته و گسسته پشتیبانی میکند.
Range | Default | Parameter |
(0,100) | 30 | HOLDOUT_PERCENTAGE |
(…,…) | 0 | HOLDOUT SEED |
[0,65535] | 255 | MAXIMUM_INPUT_ATTRIBUTES |
[0,65535] | 255 | MAXIMUM_OUTPUT_ATTRIBUTES |
[2,65535],0 | 100 | MAXIMUM STATES |
(…,0] | 10000 | SAMPLE SIZE |
6 – مایکروسافت Naïve Bayes
احتمال ارتباط میان تمامی ستونهای ورودی و ستونهای قابل پردیکشن را پیدا میکند. همچنین این پترن ریتم برای تولید سریع Mining Structure به منظور کشف ارتباطات بسیار سودمند میباشد. تنها از ویژگیهای گسسته یا گسسته شده پشتیبانی میکند و با تمامی ویژگیهای ورودی به شکل مستقل رفتار میکند.
Range | Default | Parameter |
[0,65535] | 255 | MAXIMUM_INPUT_ATTRIBUTES |
[0,65535] | 255 | MAXIMUM_OUTPUT_ATTRIBUTES |
[2,65535],0 | 100 | MAXIMUM STATES |
(0,1) | 0.5 | MINIMUM_DEPENDENCY_PROBABILITY |
7 – مایکروسافت Neural Network
به منظور تجزیه و آنالیز دیتای ورودی پیچیده یا مسائل بیزنسی که برای آنها مقدار قابل توجهی داده Train در دسترس میباشد اما به آسانی نمیتوان با استفاده از پترن ریتمهای دیگر این قوانین را بدست آورد، استفاده میشود. با استفاده از این پترن ریتم میتوان چندین ویژگی را پردیکشن نمود. همچنین این پترن ریتم میتواند به منظور طبقه بندی برای ویژگیهای گسسته و ویژگیهای پیوسته رگرسیون مورد استفاده قرار گیرد.
Range | Default | Parameter |
(…,0] | 4.0 | HIDDEN_NODE_RATIO |
(0,100) | 30 | HOLDOUT PERCENTAGE |
(…,…) | 0 | HOLDOUT SEED |
[0,65535] | 255 | MAXIMUM_INPUT_ATTRIBUTES |
[0,65535] | 255 | MAXIMUM_OUTPUT_ATTRIBUTES |
[2,65535],0 | 100 | MAXIMUM STATES |
(…,0] | 10000 | SAMPLE SIZE |
8 – مایکروسافت Sequence Clustering
به منظور شناسائی ترتیب رخدادهای مشابه در یک دنباله استفاده میشود. در واقع این پترن ریتم ترکیبی از تجزیه آنالیز توالی و خوشه را فراهم میکند.
Range | Default | Parameter |
(…,0] | 10 | CLUSTER COUNT |
[2,65535],0 | 64 | MAXIMUM_SEQUENCE_STATES |
[2,65535],0 | 100 | MAXIMUM STATES |
(…,0] | 10 | MINIMUM SUPPORT |
9 – مایکروسافت Time Series
به منظور تجزیه و آنالیز دیتای زمانی (دیتای مرتبط با زمان) در یک درخت تصمیم گیری خطی استفاده میشود. پترن های کشف شده میتوانند به منظور پردیکشن مقادیر آینده در سریهای زمانی استفاده شوند.
Range | Default | Parameter |
[0.0,1.0] | 0.6 | AUTO_DETECT_PERIODICITY |
(1.0,…) | 0.1 | COMPLEXITY_PENALTY |
ARIMA,ARTXP,MIXED | MIXED | FORECAST METHOD |
[0,100] | 1 | HISTORIC_MODEL_COUNT |
(…,1] | 10 | HISTORIC_MODEL_GAP |
[0.0,1.0] | 1.0 | INSTABILITY_SENSITIVITY |
[…,column maximum] | 1E308+ | MAXIMUM_SERIES_VALUE |
[column minimum,…] | 1E308- | MINIMUM_SERIES_VALUE |
(…,1] | 10 | MINIMUM SUPPORT |
None,Previous,Mean | None | MISSING_VALUE_SUBSTITUTION |
{…list of integers…} | {1} | PERIODICITY_HINT |
[0.0,1.0] | 0.5 | PREDICTION SMOOTHING |
دوره های مرتبط
دوره کامل تضمینی هوش تجاری با رویکرد کسب درآمد در داخل و خارج از کشور
آنالیز داده و هوش تجاری یکی از پردرآمدهای شغل های دنیا چه در داخل کشور و چه خارج از کشور است. ما در دوره آموزشی صفر تا صد هوش تجاری را به صورت تضمینی آموزش میدهیم.

آموزش ویدیویی هوش تجاری در SQL
شما در این دوره آموزشی با مفاهیم و اصول هوش تجاری در SQL آشنا می شوید و متوجه می شوید که برای ساخت یک داشبورد در هر نرم افزاری نیاز به چه مراحل و اصول و پایه هایی دارید همچنین با سیستم های هوش تجاری بزرگ آشنا شده و خود را برای تحلیل طراحی و پیاده سازی یک سامانه هوش تجاری آماده می کنید.

آموزش کامل دوره مقدماتی داده کاوی
شما در دوره مقدماتی داده کاوی با مفاهیم و اصول داده کاوی در SQL آشنا می شوید و متوجه می شوید که برای ساخت یک داشبورد در هر نرم افزاری نیاز به چه مراحل و اصول و پایه هایی دارید.

دوره آموزش داده کاوی در SSAS
شما در این دوره آموزشی (دوره آموزش داده کاوی در SSAS) با مفاهیم و اصول داده کاوی در SQL آشنا می شوید و متوجه می شوید که برای ساخت یک داشبورد در هر نرم افزاری نیاز به چه مراحل و اصول و پایه هایی دارید.

دیدگاهتان را بنویسید